AG-Blog | Datenkompetenz als Schlüssel für gemeinwohlorientierte Datennutzung
Welche Bedeutung hat Datenkompetenz für den gemeinwohlorientierten Einsatz von Daten und wie kann sie der Gesellschaft nachhaltig und wirkungsorientiert vermittelt werden? Diesen Fragen ging die AG Datendemokratie in ihrer letzten Sitzung nach.
Berlin/virtuell. Datenkompetenz ist eine Schlüsselkompetenz; gemeinsam mit der Informationskompetenz stellt sie eines der fünf Kompetenzfelder des Europäischen Rahmenmodells digitaler Kompetenzen dar. In unserer zunehmend digitalisierten und datengetriebenen Welt ist sie wichtige Grundvoraussetzung für die Teilhabe an der digitalen Gesellschaft. Dabei versteht man unter Datenkompetenz die Fähigkeit, Daten auf kritische Art und Weise zu sammeln, zu managen, zu bewerten und anzuwenden. Politisch hat die Vermittlung von Datenkompetenz vor allem durch die Datenstrategie der Bundesregierung an Bedeutung gewonnen. Am 16. März 2022 beleuchtete die AG Datendemokratie daher das Thema „Datenkompetenz als Schlüssel für Gemeinwohlorientierte Datennutzung“ aus den Perspektiven von Zivilgesellschaft, Verwaltung und Wirtschaft. Im Zentrum der Sitzung stand die Frage, welche Bedeutung Datenkompetenz für den gemeinwohlorientierten Einsatz von Daten hat und wie diese Kompetenz in der Gesellschaft nachhaltig und wirkungsorientiert vermittelt werden kann.
Nadja Kwaß-Benkow, Co-Leiterin der AG Datendemokratie, begrüßte die AG-Mitglieder und zahlreichen Gäste, indem sie die Open-Data-Strategie der Bundesregierung (die in der letzten AG-Sitzung diskutiert wurde) nochmal in Erinnerung rief und um die europäische Perspektive erweiterte: Mit dem im Februar 2022 vorgeschlagenen europäischen Datengesetz „Data Act“ wolle die Europäische Kommission zukünftig mehr Daten zur Verfügung stellen und branchenübergreifend regeln, wer welche Daten für welche Zwecke nutzen darf. Dadurch und durch einen Rechtsrahmen, der auch auf die besonderen Schutzbedürfnisse von kleinen und mittelständischen Unternehmen eingeht, solle die Datenökonomie angekurbelt werden. Ziel sei es, dass alle Akteur*innen den Vorteil darin sehen, Daten geschützt und sicher miteinander zu teilen – nur so könne ein gesellschaftlicher Mehrwert daraus generiert werden. Kwaß-Benkow verwies dabei auf die Partizipationsmöglichkeiten im laufenden öffentlichen Konsultationsprozess der Europäischen Kommission zum Thema.
Gemeinwohlorientierte Datennutzung durch Datenkompetenz: die Sichtweise der Zivilgesellschaft
Für einen Einblick in die Praxis hatten die AG-Co-LeiterInnen Nadja Kwaß-Benkow und Dr. Christian Kiehle eine Referentin eingeladen, die sich zivilgesellschaftlich tagtäglich für eine positive gesellschaftliche Entwicklung hinsichtlich Datenkompetenz einsetzt: Nina Hauser, Head of Data Literacy beim gemeinnützigen Verein CorrelAid, stellte verschiedene zivilgesellschaftliche Initiativen aus der Entwicklungszusammenarbeit und dem Bereich Citizen Science vor, die mit Daten arbeiten und für die gute Datenkompetenzen unersetzlich seien.
Neben Bildungsformaten bietet CorrelAid an, eine vermittelnde Mentor*innen-Rolle bei datenbezogenen Projekten von Organisationen einzunehmen, die Unterstützung im kostspieligen Umfeld von Datenwissenschaftler*innen benötigen, zum Beispiel:
- Erstellung der interaktiven Weltkarte „Erlassjahr“, um abzubilden, wie kritisch sich Staatsschulden im globalen Süden auf die Lebensbedingungen der Menschen auswirken, die dringend eine Entschuldung benötigen.
- Automatisierung der individuellen Jahresumfrage für Weltläden in der D-A-CH-Region, um damit Ressourcen im Prozess zu sparen.
- Entwicklung eines Systems, das anhand von Sensoren und Machine Learning auf Anomalien hinsichtlich Temperatur, Luftfeuchtigkeit und Gewicht eines Bienenstocks hinweist, um damit Imker*innen zu unterstützen und Bienen zu retten.
Bei der gemeinwohlorientierten Arbeit mit Daten sei es wichtig, die Wirkungslogik der Datennutzung in den Mittelpunkt zu stellen, so Hauser:
Datenanalyse muss viel stärker von der zu erzielenden Wirkung ausgehen und weniger von den vorhandenen Daten – von denen es im Übrigen in der Regel nie genug gibt.
Nach einer Prüfung der für die Problemstellung relevanten öffentlichen Datenquellen sei die Zielgruppe der evidenzbasierten Wirkung zu definieren. Dabei komme es darauf an, dass man den Input effizient und effektiv gestalte, um die Wirkung zu maximieren. Bei Fundraisingkampagnen von NGOs sei zum Beispiel üblicherweise die zu erzielende Wirkung „Finanzierung sichern“; die Messbarkeit des Ergebnisses erfolge dann anhand des Umfangs der tatsächlichen Finanzierung. Besonders wichtig sei es laut Hauser, dass neben den Vorgaben und Zielen auch vorab definiert werde, wie die Daten zu interpretieren seien. Viel zu selten stelle man sich die Frage, ob überhaupt eine Wirkung erzielt wurde oder ob es sich nur um einen (Neben-)Effekt ohne kausalen Zusammenhang handle.
Hausers Appell
für die Zukunft: Eine Aufgabe für die Bildungspolitik, aber auch für
Datenanalyst*innen in Unternehmen müsse es sein, Wissen, Kompetenzen und
Bildungsangebote zur Erlangung von Datenkompetenz niederschwellig zu
halten und für eine breite Bevölkerungsschicht zugänglich zu machen: „Weiterbildungen
im Bereich Datenkompetenz sind teuer, oft fehlen in Unternehmen,
Vereinen und der Verwaltung Ressourcen dafür. Umso wichtiger ist es,
dass wir Möglichkeiten für kostengünstige oder sogar kostenlose
Lernanlässe schaffen.“
Data Literacy – Warum Datenkompetenz demokratische Strukturen stärkt
Diesen Faden griff Dr. Daniel Vorgrimler (Direktor beim Statistischen Bundesamt) auf, der „interessens- und berufsbedingt keine Angst vor Zahlen und Statistik“ kennt. Datenkompetenz, die auf der Fähigkeit zur Interpretation statistischer Daten basiere, brauche eine einfache und leicht zugängliche Sprache, so Vorgrimler. Denn Statistik sei kein Feind, den niemand verstehen könne, wie sie oft dargestellt würde: Statistik diene dazu, Entscheidungen besser zu machen. Sie helfe dabei, dass diese Entscheidungen mit einer höheren Wahrscheinlichkeit richtig sind. Das gelte für die Politik genauso wie für unseren Alltag.
Tatsächlich werde Statistik im politischen Umfeld, sei es in den klassischen Medien, bei Social Media oder in der Kommunikation politischer Entscheidungen, oft dazu benutzt, Agenda Setting zu betreiben:
Statistik darf Politik nicht ersetzen. Eine zu starke Kausalität zwischen Statistiken und politischen Entscheidungen erhöht den Druck auf Menschen, die Statistiken erheben, immens. Das kann für die Neutralität der Wissenschaft zum Problem werden.
Der eigentliche Sinn von Statistik sei es, Hypothesen zu belegen oder eben zu widerlegen. Problematisch sei es, wenn mit der Fehlinterpretation oder sogar dem Missbrauch von statistischen Daten Fehlschlüsse gezogen würden. Als treffendes Beispiel für solche Fehlschlüsse führte Vorgrimler die Frage an, wo die Wahrscheinlichkeit für einen Tsunami höher sei, in Kalifornien oder in Nordamerika. Seiner Erfahrung nach werde diese Frage häufiger mit „Kalifornien“ beantwortet, da der kausale Zusammenhang, dass es in Kalifornien überdurchschnittlich häufig Tsunamis gibt, beim Nachdenken über die Frage schwerer wiege als die Tatsache, dass Kalifornien eine Teilmenge von Nordamerika ist.
An die Politik formulierte Vorgrimler den Anspruch, man müsse sich rechtzeitig der Frage stellen, wir wir es schaffen, in einer Krise möglichst schnell die relevanten Daten zu generieren und für die Gesellschaft adäquat zu aggregieren. „Dieser Herausforderungen haben wir uns im Kontext der COVID-19 Pandemie stellen müssen und werden es auch in weiteren Krisen tun müssen.“
Vorgrimler schloss ebenfalls mit einem Appell: Die Aufgabe für Schulen, Hochschulen aber auch für den Journalismus sei es jetzt, Zahlen, Daten und Fakten korrekt auszuwerten und in einer einfachen Sprache zu vermitteln. So könnten unsere demokratischen Strukturen gestärkt werden.
Datenkompetenz ist für uns alle gut.
Sei es, um Statistiken lesen und interpretieren zu können, aber auch um manipulative Darstellungen wie beispielsweise abgeschnittene Achsen und Stichproben, die das Ergebnis vordeterminieren, zu entlarven.
Beide Impulse lieferten Diskussionsstoff, um Datenkompetenz in der gemeinwohlorientierten Datennutzung aus den Blickwinkeln von Politik, Verwaltung, Wirtschaft und Zivilgesellschaft zu beleuchten. Die AG Datendemokratie konnte damit einen interessanten Sitzungsvormittag bestreiten, der zahlreiche Anknüpfungspunkte bietet, um das komplexe Thema Datenkompetenz handhabbarer zu machen und in die eigenen Organisationen zu tragen.
Wiederwahl der AG-Leitung
Den Abschluss der ersten diesjährigen AG-Sitzung bildete die turnusgerechte Wahl der AG-Leitung. Die amtierenden Vorsitzenden Dr. Christian Kiehle (msg systems AG) und Nadja Kwaß-Benkow (Materna Information & Communication SE, D21-Vorständin) wurden wiedergewählt und werden auch im nächsten Jahr die AG-Co-Leitung übernehmen. Herzlichen Glückwunsch zur Wiederwahl!
Exkurs: Datenkompetenzen bei der Interpretation des Zufalls
Nach mehr als zwei Jahren Pandemie haben die meisten von uns das ein oder andere virtuelle Meeting als Videokonferenz hinter sich. Neben dem geplanten Wiedersehen in Präsenz beim nächsten Treffen der AG Datendemokratie spielten in dieser AG-Sitzung aber auch andere Wiedersehen eine Rolle: Die Teilnehmenden diskutierten in mehreren Runden in Breakout-Räumen über das Thema Datenkompetenz im eigenen (Arbeits-)Alltag. Dabei fiel einigen Teilnehmenden auf, dass sie gefühlt häufig in mehreren Diskussionsrunden die gleichen PartnerInnen wiedersahen, obwohl die Zusammensetzung der Räume zufällig zusammengestellt wurde. Aber wie hoch ist tatsächlich die Wahrscheinlichkeit, dass mindestens eine Person bei der zufälligen Zuweisung zu Breakout-Räumen jemandem zweimal begegnet?
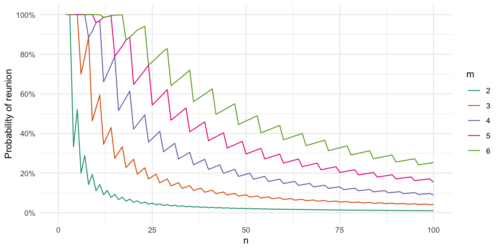
In der AG-Sitzung wurden 20 Teilnehmer*innen mehrmals hintereinander in Gruppen à vier Personen aufgeteilt. In dieser Konstellation landen wir also bei einer Wahrscheinlichkeit von über 40 Prozent dafür, dass mindestens eine teilnehmende Person in der zweiten Runde jemanden wiedersieht. Obwohl es sich weniger zufällig anfühlt, mit den gleichen Leuten zusammengewürfelt zu werden, kann also durchaus der Zufall dahinterstecken. Die (mangelnde) Datenkompetenz in Bezug auf den Zufall sorgte in der Vergangenheit zum Beispiel schon dafür, dass Streaminganbieter wie Spotify ihren Zufallsalgorithmus weniger zufällig machten – den Nutzer*innen kam es zu wenig zufällig vor, wenn mehrere Lieder der gleichen Band nacheinander in ihrer Playlist landeten.
